
- 분류 전체보기 (54658)

- 유엔 (599)
- 수소핵폭탄(핵탄두) 실험과 KN-08 (1979)
- 뇌 분해감청팀으로 국제사건 자료 (34)
- 부호들의 이야기(평민적 자본가 삶) (14)
- Guide Ear&Bird's Eye (331)
- Guide Ear&Bird's Eye2 (906)
- Guide Ear&Bird's Eye3 (214)
- Guide Ear&Bird's Eye4 (28)
- Guide Ear&Bird's Eye5 (3)
- Guide Ear&Bird's Eye6 (938)
- Guide Ear&Bird's Eye7 (15)
- 국가정보원 안보모니터 (372)
- 경찰 머리소리함[Bird' Eye](i) (5)
- 감사원 (13)
- 핵.잠수함.미사일.전자 지능 뇌 자료 (459)
- Guide Ear&Bird's Eye8 (1397)
- Guide Ear&Bird's Eye9 (556)
- Guide Ear&Bird's Eye10 (648)
- Guide Ear&Bird's Eye11 (74)
- Guide Ear&Bird's Eye12 (293)
- 자유화 민주화운동 세력-탈북민 자료 (420)
- Guide Ear&Bird's Eye13 (613)
- Guide Ear&Bird's Eye14 (215)
- CIA.FBI(귀가 빙빙 도는 뇌 감청기) (574)
- Guide Ear&Bird's Eye15 (807)
- 아시아 (8)
- 同一介中華(中國) (2662)
- Guide Ear&Bird's Eye16 (380)
- Guide Ear&Bird's Eye17 (243)
- Guide Ear&Bird's Eye18 (2)
- 장족(좡족 ,광서) (0)
- Guide Ear&Bird's Eye19 (0)
- Guide Ear&Bird's Eye20 (0)
- 동북아[극동] (0)
- Guide Ear&Bird's Eye21 (1236)
- Guide Ear&Bird's Eye22 (4643)
- Guide Ear&Bird's Eye23 (50)
- Guide Ear&Bird's Eye24 (2360)
- Guide Ear&Bird's Eye25 (0)
- Guide Ear&Bird's Eye26 (17)
- Guide Ear&Bird's Eye27 (29)
- 미국 알래스카 주(극동) (2)
- 동남아시아 (39)
- Guide Ear&Bird's Eye28 (14)
- Guide Ear&Bird's Eye29 (115)
- Guide Ear&Bird's Eye30 (457)
- Guide Ear&Bird's Eye31 (43)
- Guide Ear&Bird's Eye32 (162)
- Guide Ear&Bird's Eye33 (7)
- Guide Ear&Bird's Eye34 (23)
- Guide Ear&Bird's Eye35 (2)
- Guide Ear&Bird's Eye36 (39)
- Guide Ear&Bird's Eye37 (85)
- Guide Ear&Bird's Eye38 (75)
- 벵골만 주변국 정상회의 (1)
- Guide Ear&Bird's Eye39 (146)
- Guide Ear&Bird's Eye40 (403)
- 중앙아시아 (43)
- Guide Ear&Bird's Eye41 (552)
- Guide Ear&Bird's Eye42 (94)
- Guide Ear&Bird's Eye43 (422)
- Guide Ear&Bird's Eye44 (387)
- Guide Ear&Bird's Eye45 (138)
- Guide Ear&Bird's Eye46 (834)
- Guide Ear&Bird's Eye47 (0)
- 유럽[Europe, 歐羅巴] (0)
- 유럽연합(EU) (136)
- 동유럽 지역 (38)
- 흑해 주변국 (577)
- 북유럽 지역 (48)
- 중부 유럽 지역 (146)
- Guide Ear&Bird's Eye48 (40)
- 서유럽 지역 (0)
- Guide Ear&Bird's Eye49 (348)
- Guide Ear&Bird's Eye50 (165)
- Guide Ear&Bird's Eye51 (8)
- 남유럽 지역 (46)
- Guide Ear&Bird's Eye52 (16)
- 아프리카 (0)
- Guide Ear&Bird's Eye53 (23)
- 북아프리카 지역 (458)
- Guide Ear&Bird's Eye54 (34)
- 중앙아프리카(중부아프리카) 지역 (9)
- Guide Ear&Bird's Eye55 (26)
- 남부 중앙아프리카 지역 (21)
- 남아프리카 지역 (40)
- 아메리카 (1)
- 북아메리카 지역 (0)
- Guide Ear&Bird's Eye56 (1641)
- Guide Ear&Bird's Eye57 (38)
- Guide Ear&Bird's Eye58 (18)
- 중앙 아메리카 지역 (99)
- 남아메리카 지역 (136)
- 오세아니아 지역 (76)
- 5대양 (0)
- 대한민국 전직대통령 자료 (232)
- 2단계 민주화-민주(문민)정부 수립 (127)
- -국가주석이나 대통령 임기제한 (162)
- -平和大忍, 信望愛. (730)
- ->제1, 2, 3공화국 구분(북한역사) (75)
- '三國志[사람됨 교육장소-仁德政治]" (137)
- [NATO 모델] (151)
- Guide Ear&Bird's Eye59 (4318)
- -미국 언론- (8180)
- 한중 육로개척자 -延邊 藥山 진달래 (53)
- 한일해저터널 개척자-東京 櫻花 (15)
- 세계각국 자유사회 인물 발굴-許灌 (7)
- 대북정책 (101)
Asia-Pacific Region Intelligence Center
인공지능(AI)이 똑똑해진 비결은? ‘기계학습’ 본문
“오늘 날씨가 어때? 우산을 챙겨야 할까?”, “최신 아이돌 노래를 틀어 줘”라고 스마트 스피커나 스마트폰에 말을 걸어본 적 있나요? 직접 버튼을 누르지 않아도, 우리의 목소리를 인식해 질문에 대답하거나 명령을 수행해 줍니다. 사진을 찍으면 누가 누구인지 얼굴을 인식해 구별해주고, 취향에 맞는 동영상이나 음악 알고리즘을 추천해주기도 합니다. 영어나 중국어, 일본어 등 외국어를 바로바로 번역해주기도 하죠.
이 모든 일을 하는 주인공은 바로 ‘인공지능(AI)’입니다. 그동안 AI는 SF 영화 속에서만 만나볼 수 있었지만, 기술의 발전으로 어느덧 일상 속 곳곳에 침투해 우리 생활을 편리하게 만들어주고 있어요. AI가 어떻게 지금처럼 똑똑해질 수 있었는지 함께 알아볼까요?

AI 연구의 시작과 발전 과정
AI는 사람처럼 생각하고, 배우고, 행동할 수 있도록 설계된 컴퓨터나 기계를 말합니다. 과학자들은 오래전부터 인간의 지능을 닮은 기계를 개발하고 싶어 했습니다. 그러던 중 1950년 영국의 수학자인 앨런 튜링은 언젠가 모든 면에서 인간의 지능을 따라 할 수 있는 기계가 등장할 것으로 예측하며, 이를 증명하기 위한 특별한 테스트를 생각해 냈습니다.
‘튜링 테스트’라고 불리는 이 시험에는 두 명의 참가자가 등장합니다. 한 명은 인간이고, 다른 한 명은 기계(컴퓨터 프로그램)죠. 이들과 대화를 나누면서 어느 쪽이 컴퓨터인지 구분할 수 없다면, 그 컴퓨터는 튜링 테스트를 통과한 것이고, 인간 수준의 지능을 달성했다는 것을 뜻합니다. 튜링 테스트는 AI 발전에 중요한 이정표가 되었습니다.

그리고 1955년, 미국의 수학자 존 매카시가 ‘인공지능’이라는 말을 처음으로 만들어내며 AI를 개발하려는 연구들이 비로소 시작되었습니다. 하지만 당시는 컴퓨터의 성능이 매우 낮아 AI의 개발 속도는 매우 더뎠습니다. 체스를 두는 컴퓨터처럼 간단한 AI가 개발되기 시작했지만, 지금과 같은 성능은 아니었죠. 그러다 1990년대부터 컴퓨터 기술이 크게 발전하면서 AI 연구가 부활하기 시작했고, 지금과 같은 똑똑한 AI가 등장하게 되었답니다.
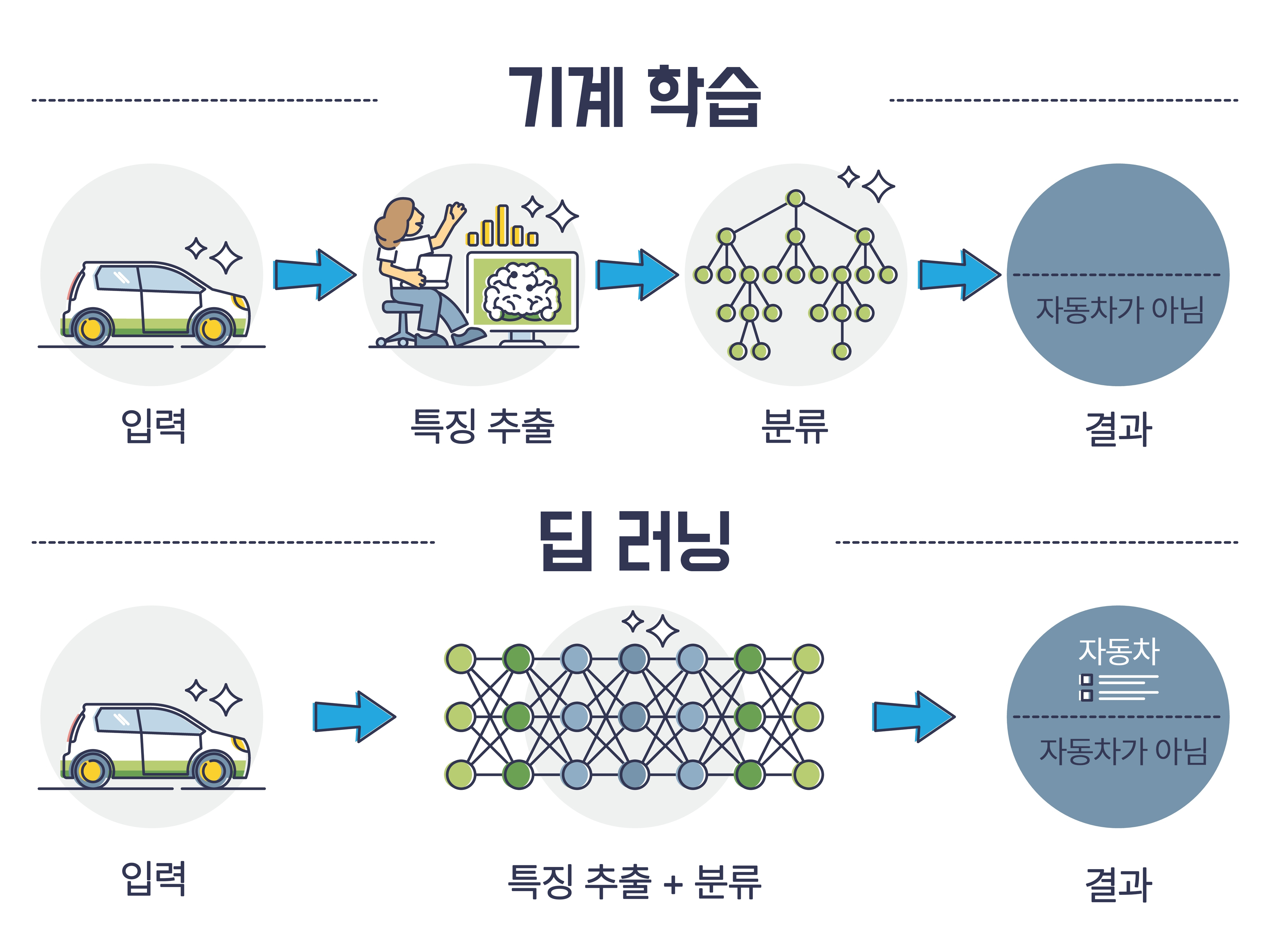
기계학습으로 똑똑해진 AI
그렇다면 AI는 어떻게 똑똑해질 수 있었을까요? 바로 ‘기계학습’이라는 기술 덕분입니다. 우리가 책을 읽고 공부하며 성장하는 것처럼, 인공지능은 데이터를 학습하며 똑똑해집니다. 이때 AI는 역할에 따라 숫자, 글, 사진, 음악, 영상 등 다양한 데이터를 이용합니다. 예를 들어 음성 인식 AI는 사람의 목소리가 녹음된 데이터를 학습하죠.
AI는 데이터를 학습해, 패턴을 찾아내고 모델을 만듭니다. 그리고 이 모델을 사용해서 새로운 데이터를 처리하고, 결과를 예측하거나 판단합니다. 음성 인식 AI의 경우, 학습된 모델로 사람의 말을 이해하고 대답할 수 있게 되는 거예요. 만약 AI의 성능이 좋지 않다면, 추가로 데이터를 더 학습해 성능을 개선하기도 합니다. 우리가 수학 문제를 여러 번 연습해 풀면서 실력을 높이는 것과 같습니다.
이런 기계학습에는 여러 종류가 있는데요, 가장 대표적인 것이 ‘딥러닝’입니다. 딥러닝은 우리 뇌를 본떠 만든 ‘인공 신경망’을 이용하는데요, 다른 기계학습과 가장 큰 차이점은 바로 AI가 ‘스스로’ 학습을 할 수 있다는 것입니다. 딥러닝이 등장하기 전까지는 인간이 직접 AI에게 데이터에서 어떤 패턴을 파악해야 하는지를 정해주었습니다. 하지만 딥러닝 기술을 활용하면 AI가 데이터만 보고도 그 속의 숨겨진 패턴과 특징을 스스로 학습할 수 있습니다. 정확도도 매우 높아, 딥러닝 방식으로 학습한 AI들은 특히 이미지·음성 인식 등에서 뛰어난 성능을 보여주고 있답니다.
좋은 AI를 만들기 위해서는 품질 좋은 데이터가 중요!
지금까지 살펴본 것처럼, AI가 똑똑해질 수 있었던 비결은 데이터 학습입니다. 그래서 AI에게 주어지는 데이터가 매우 중요해졌는데요, 학습할 데이터의 양이 부족하거나, 잘못된 데이터로 학습하면 AI가 잘못된 판단을 내릴 수 있기 때문입니다. 그렇기에 좋은 AI를 만들기 위해서는 품질이 좋은 데이터를 활용해야 하죠.
하지만 품질이 좋은 데이터를 모으고, 또 AI가 쓸 수 있도록 가공하려면 시간과 비용이 많이 듭니다. 이에 한국과학기술정보연구원(KISTI)에서는 ‘에이다(AIDA)’라고 불리는 AI 데이터 공유·활용 서비스를 운영해 연구자들이 과학기술 분야의 AI 데이터를 자유롭게 쓸 수 있도록 지원하고 있습니다. 텍스트, 이미지, 동영상 등 여러 유형의 데이터를 제공하고 있으며, 데이터를 학습하여 필요한 모델을 만들 수 있는 프로그래밍 환경도 지원하고 있습니다.
앞으로 AI는 더욱 빠른 속도로 발전해, 우리 삶에도 더 큰 변화를 가져올 것입니다. AI와 함께 살아가는 것이 더 이상 놀랍지 않게 되겠죠. 그러므로 우리는 AI와 함께 성장해 나갈 수 있도록 AI에 대해 배우고 이해하며, 어떻게 하면 AI를 효율적이고 올바르게 활용할 수 있을지를 고민해야 할 것입니다.

글: 오혜진 동아에스앤씨 기자 / 일러스트: EZ쌤
'Guide Ear&Bird's Eye6 > 4차 산업을 찾다' 카테고리의 다른 글
| UAM·S-BRT 미리 만나보는 미래 교통 기술 (0) | 2024.05.16 |
|---|---|
| 삼성전자, ‘Unbox & Discover 2024’ 개최… AI TV 시대 선언 (0) | 2024.05.14 |
| 스포츠에 불어든 AI 바람 (0) | 2024.05.13 |
| 갤럭시 AI 글로벌 연구소 1화: 인도네시아(SRIN) (0) | 2024.05.12 |
| 슈퍼컴퓨터 '후가쿠'로 개발된 AI 완성돼 보도진 공개 (0) | 2024.05.12 |
'Guide Ear&Bird's Eye6/4차 산업을 찾다' Related Articles
more



